SEO ON-PAGE EVALUATOR
Bulk SEO on-page analysis.
More than 30 signals watched...
...and increasing
INSTRUCTIONS:
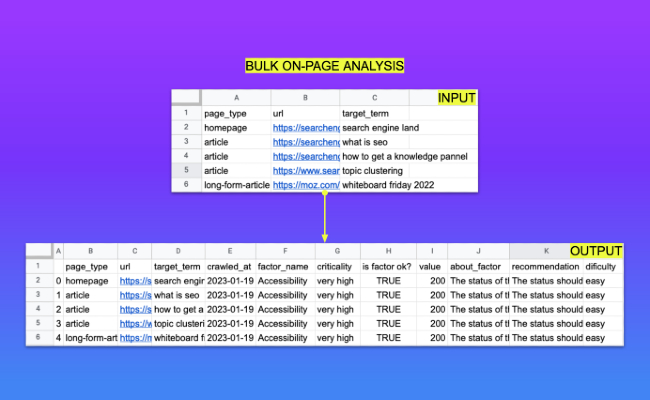
- Download the input csv example above.
- Fill the cells with following values: page_type (the type of page you intend to analyse - possible values are 'article','news-article','long-form-article','homepage','product-page' and 'list'), url (the url you need to be analized), target_term (the target term you intend to run the analysis over).
- Upload your csv and wait for the download with your results.
HOW ON-PAGE SEO EVALUATOR WORKS:
class OnPage:
A class for analyzing on-page SEO factors of web pages.
Attributes:
zip_arr : dict
A dictionary containing the URL, page type and target term information of the web pages to be analyzed.
onpage_to_df : pandas DataFrame
A DataFrame containing the merged information of the `zip_arr` dictionary and the results of the web page analysis.
target_term : numpy ndarray
A lowercased ndarray of the target terms of the web pages.
Methods:
crawled_at()
Returns the crawl times of the web pages.
target_template()
Returns the lowercased page types of the web pages.
target_url()
Returns the lowercased URLs of the web pages.
target_term()
Returns the lowercased target terms of the web pages.
is_status_200()
Returns a list of the accessibility factor 'Accessibility', its criticality, a list of booleans indicating whether the status code of each web page is 200 OK, a list of the status codes, the description of the factor, the recommendation for improvement, and the difficulty of improvement.
has_canonical()
Returns a list of the on-page SEO factor 'use of the canonical link tag', its criticality, a list of booleans indicating whether each web page has a canonical link tag, a list of the values of the canonical link tags (or '-' if there is no tag), the description of the factor, the recommendation for improvement, and the difficulty of improvement.
has_one_canonical()
Returns a list of the on-page SEO factor 'no more than one canonical tag per page', its criticality, a list of booleans indicating whether each web page has no more than one canonical tag, a list of the number of canonical tags on each web page, the description of the factor, the recommendation for improvement, and the difficulty of improvement.
is_canonical_self_ref()
Returns a list of the on-page SEO factor 'self-referenced canonical tag', its criticality, a list of booleans indicating whether each web page has a self-referenced canonical tag, a list of the values of the canonical tags (or '-' if there is no tag), the description of the factor, the recommendation for improvement, and the difficulty of improvement.
has_meta_robots()
The method has_meta_robots returns a list that contains the following elements: (to be done...)
is_meta_robots_indexable()
The is_meta_robots_indexable method returns a list of information related to the indexability of web pages by search engines. The list includes the name of the recommendation, its criticality, an array of boolean values indicating whether each page in a data frame is indexable by search engines based on its "meta_robots" value, an array of lowercased "meta_robots" values if it exists, a description of the role of the "meta_robots" tag in web pages, a recommendation for the proper use of the "meta_robots" tag, and an indication of the difficulty of the recommendation. The information provided by the method helps webmasters to ensure that pages containing important content or meant to be found by users are not blocked from being indexed by search engines, and that pages that should be blocked from being indexed are properly tagged.
has_title()
The method has_title returns a list of values that describe the presence of the title tag in the page. The method first checks if the 'title' column exists in the dataframe onpage_to_df. If it does, the method sets the values of has_title to a Boolean array that indicates whether each row in the 'title' column has a value or not, and sets the values of title to an array that contains the lowercase strings of the 'title' column. The length of the 'title' column is also stored in title_len. If the 'title' column doesn't exist in onpage_to_df, both has_title and title are set to False. The method also stores information about the importance of the 'title' tag and its recommended usage in a dictionary called about. The method returns a list that consists of about['name'], about['criticality'], has_title, title, about['description'], about['recommendation'], and about['difficulty'].
is_title_len_right()
The method is_title_len_right returns a list that contains the name, criticality, and information regarding the length of the title tag in a webpage. If the 'title' key is present in the data frame onpage_to_df, the method calculates the length of the title and checks if it is within the range of 50 to 60 characters, which is considered appropriate. The result of this check is stored in is_title_len_right, a list of booleans indicating if the length of each title is within the appropriate range. If the 'title' key is not present in the data frame, the method sets is_title_len_right to False and title_len to 0. Additionally, the method includes a dictionary about that contains information about the importance of the title length, its recommendation, and difficulty level. The final list returned by the method includes the information from the about dictionary and the values of is_title_len_right and title_len.
has_one_title()
The method has_one_title checks the presence of only one title element on a page. It takes the title column from the onpage_to_df dataframe and checks if the number of times the title is split using the '@@' separator is equal to 1 for each row. If the title column exists in the dataframe, the method returns a list that consists of the name of the check, its criticality, a list of boolean values indicating whether each row has only one title or not, the number of times each title is split using '@@', a description of the importance of having only one title element, a recommendation to have only one title element on each page, and the difficulty of implementing the recommendation. If the title column does not exist in the dataframe, the method returns False for both has_one_title and title_times.
is_in_title()
The method is_in_title() returns a list containing information about the presence of the target term in the page's title tag. If the "title" column is present in the "onpage_to_df" dataframe, the method checks if the target term is present in each page's title tag using regular expressions and returns two lists: one indicating if the target term is present in the title (is_in_title) and one indicating the number of times the target term is present in the title (times_in_title). If the "title" column is not present in the "onpage_to_df" dataframe, the method returns False for both is_in_title and times_in_title. Additionally, the method returns a dictionary (about) containing information about the purpose of the method and its importance, along with a recommendation and the difficulty of implementing it. The returned list includes the information from the dictionary and the results of the checks on the "title" column.
is_exact_in_title()
The method is_exact_in_title returns the results of a search for the exact target term in the page's title. It starts by checking if the "title" column is present in the "onpage_to_df" dataframe. If present, it converts the "target_term" and "title" columns to lowercase, and performs a regular expression search to find the exact target term in the title. The search results are stored as a boolean value in "is_exact_in_title", indicating if the target term was found exactly in the title, and the number of times it was found is stored in "exact_times_in_title". If the "title" column is not present, the values for "is_exact_in_title" and "exact_times_in_title" are set to False and 0, respectively. Finally, the method returns the name of the test, its criticality, the search results, the description, recommendation, and difficulty of the test.
is_exact_in_title_begin()
The method is_in_title_begin returns the result of whether the target term of the document appears at the beginning of the title tag in the web page data. The result is a boolean value of either True or False, indicating if the target term appears at the start of the title tag. The method also returns additional information such as the name of the method, the criticality of the placement of the target term in the title tag, the description of the impact of the placement, the recommendation for best placement, and the difficulty level of following the recommendation.
is_less_2x_in_title()
The method is_less_2x_in_title returns a list of values including the name of the optimization practice (avoid excessive use of the target term in the document's title), its criticality level (high), a list of booleans indicating whether the target term appears less than or equal to 2 times in the document's title for each record, a list of integers representing the number of times the target term appears in the title for each record, a description of the optimization practice, a recommendation to avoid having the target term occur more than 2 times in the page's Title, and the difficulty level of the optimization practice (easy).
has_description()
Returns a list of the on-page SEO factor 'description tag', its criticality, a list of booleans indicating whether each web page has a description tag, a list of the values of the description tags (or '-' if there is no tag), the description of the factor, the recommendation for improvement, and the difficulty of improvement.
has_h1()
Returns a list of the on-page SEO factor 'H1 tag', its criticality, a list of booleans indicating whether each web page has an H1 tag, a list of the values of the H1 tags (or '-' if there is no tag), the description of the factor, the recommendation for improvement, and the difficulty of improvement.
has_h2()
Returns a list of the on-page SEO factor 'H2 tag', its criticality, a list of booleans indicating whether each web page has at least one H2 tag, a list of the